GGUF 与量化
前言:今天在看 GGUF,记录一下。之前用过几次 gguf 的模型,但是一直不理解啥意思,所以来看了看。
Part 1: GGUF 文件二进制布局
先放一张官方图:

上图是 gguf 文件的二进制布局。整体结构大概是:
Header → Metadata block → Tensor Info array → Padding → Tensor Data
1. Header(头部)
也就是图中左上角四个小黑条,包含以下四部分:
- Magic Number (4 bytes):
GGUF。这是魔数,告诉计算机“这是一个 GGUF 文件”。对应的十六进制0x47 0x47 0x55 0x46正是 ASCII 码的 G-G-U-F。 - Version (4 bytes): 版本号。图中显示
currently = 3(目前主流也是 v3)。 - Tensor Count (8 bytes): 模型里有多少个张量(权重矩阵)。
- Metadata KV Count (8 bytes): 有多少组元数据(键值对)。表示下面元数据部分有多少个键值对。
2. Metadata(元数据)- 绿色小条
里面有 Metadata KV Count 个 Key-Value 对。每个 KV 对都表示模型的某个配置信息。例如图中就有:
general.architecture: 模型架构(如 “llama”)。llama.context_length: 上下文长度(如 4096)。tokenizer.ggml.tokens: 分词器的词表。
3. Tensors Info(张量信息)- 紫色小条
权重的索引表,共有 Tensor Count 个。每个里面包含:
name: 张量的名字(如blk.0.ffn_gate.weight,即第0层的前馈网络权重)。dimensions: 形状(如[4096, 32000])。type: 数据类型。支持各种量化格式(Q4_K, Q8_0, FP16 等),极大地压缩了体积。(看到这里发现对量化也一知半解)offset: 这是一个偏移量,表示当前 tensor 对应的实际数据在哪里,可以利用这个 offset 直接定位读取。据说这里的 offset 是相对 tensor_data 块起始位置的偏移量,但我没去看细节。
4. Tensor Data(二进制张量数据)- 右侧黑色条
- 内容: 纯粹的二进制 0101… 数据。
- 对齐(Alignment): 为了让 CPU/GPU 读取更快,这些数据通常会按照 32 字节或 64 字节对齐(图中黑色条块中间的空隙就是 padding)。默认是 32 字节。
- 工作原理: 加载器读取了“第三部分”里的
offset后,直接跳到这里对应的位置读取数据,或者直接mmap映射。
Part 2: 为什么 GGUF 能跨平台且支持混合推理?
1. 内存映射与零拷贝
文件里的二进制数据布局,和 C/C++ 语言在内存里存数组的布局完全一致。所以可以用 mmap 进行内存映射,实现零拷贝加载。GPU offloading 需要显存拷贝,mmap 主要让 CPU 读得快。
2. 对齐与 SIMD 友好 将张量数据切分成特定大小的 Block,这些块的大小(如 32 字节)正好是 CPU 寄存器一次能处理的数据宽度的倍数。
- 在
constants.py中,GGUF_DEFAULT_ALIGNMENT被设置为 32 字节。 GGUFWriter在写入张量数据前,会调用ggml_pad函数计算补齐长度。write_padding函数会在两个张量之间填充空字节。
3. 层级卸载 (Layer Offloading)
原理:大模型是由一层一层的神经网络堆叠起来的(比如 Llama-2 有 32 层)。
GGUF 的优势:因为 GGUF 里的张量是独立定义的(通过 Offset 查找),加载器(如
llama.cpp)可以灵活分配“谁干什么活”。大致实现流程:
程序读取 GGUF 头部,发现有 32 层。
用户设定
n_gpu_layers = 20(把前 20 层扔给显卡)。程序把 GGUF 文件中前 20 层的张量数据直接拷贝到 GPU 显存(VRAM)。(实际运行时不是整层移动,而是移动 tensor 级别,这样效果更好)
懒得看源码了,但是找到了一篇帖子,感觉应该是两种方式都可行,但是 tensor 更好,后面要是用到我再去看看 https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7/dont_offload_gguf_layers_offload_tensors_200_gen/
剩下的 12 层数据留在系统内存(RAM),由 CPU 计算。
数据先在 GPU 跑完前 20 层,结果传回 CPU,CPU 跑完剩下 12 层。
4. 针对 Mac 的优化 M 系列芯片是统一内存架构,CPU 和 GPU 共用同一块内存,GGUF 加载的数据,CPU 能看,GPU 也能看,几乎不需要数据拷贝。
Part 3: 关于量化
1. 对称量化
例如假设有一层的权重,范围是从 -100.0 到 +100.0。
把它压缩成 8-bit 整数(范围 -128 到 127)。可以把 -100 映射成 -128,把 +100 映射成 +127,中间的数按比例缩放。
- 问题: 因为权重可能是稀疏的,分布不均匀的,当大部分值比较小,少部分值很大时,精度损失很严重。所以有下面的分块量化。
2. 非对称量化
基本被弃用 非对称量化将浮点值范围 $[min, max]$ 映射到整数区间。这个范围不一定关于原点对称。
- 核心逻辑:引入一个偏移量,使得浮点数中的 $0$ 可以对应整数中的非零值。
- 数学表示:$Q = \text{round}(x / S + Z)$,其中 $Z$ 是零点偏移。
3. 分块量化 (Block Quantization)
其实就是分块进行量化。以下以对称量化为例:
假设我们有一排权重(32 个浮点数):[0.12, -0.55, 1.20, ...]
- 分组:把这 32 个数分成一组(Block)。
- 找极值:找出这组数里绝对值最大的数(比如 1.20)。
- 提取缩放因子 (Scale):把 1.20 存下来(存为 16-bit 浮点数)。
- 压缩:把这 32 个数都除以 1.20,然后强行映射到
-8到+7之间的整数(4-bit)。 - 存储:
- 硬盘上存:
1 个缩放因子+32 个 4-bit 整数。 - 总大小:
2 bytes (scale) + 16 bytes (data) = 18 bytes。 - 原大小(如果存 FP16):
32 * 2 bytes = 64 bytes。 - 压缩率:接近 1/4
- 硬盘上存:
- 计算时的解压缩:读取 4-bit 整数 → 乘以缩放因子 → 恢复成近似的浮点数 → 进行矩阵乘法。
Part 4: K-Quants (K-Points Quantization)
模型里不同的层,重要性是不一样的。
v向量(Attention Value)和output层非常敏感,所以要用高精度。ffn层(前馈网络)不敏感,可以选择低精度。
Q4_K_M、Q5_0 中的 K, M, 0 都是什么含义?
- Q:表示量化。
- K:就是上面的 K-Quants。
- 后缀 S, M, L:感觉和衣服尺码差不多,表示不同比例的层是低精度的:
_K_S: Small / 更紧压缩 + 更低 quality。_K_M: Medium balance。_K_L: Larger / 更高 quality。- 具体策略主要是不同 block 划分 + scale estimation。
- 后缀 0:基础的分块 + 对称量化。
- 后缀 1:基础的分块 + 非对称量化。
Part 5: 去看了看现在的模型 (Kimi 2.5 & Qwen 3)
Kimi-K2.5-GGUF
unsloth/Kimi-K2.5-GGUF · Hugging Face 看了看刚出的 kimi2.5 的 gguf, 1-16bit 都有,虽然我都跑不了。
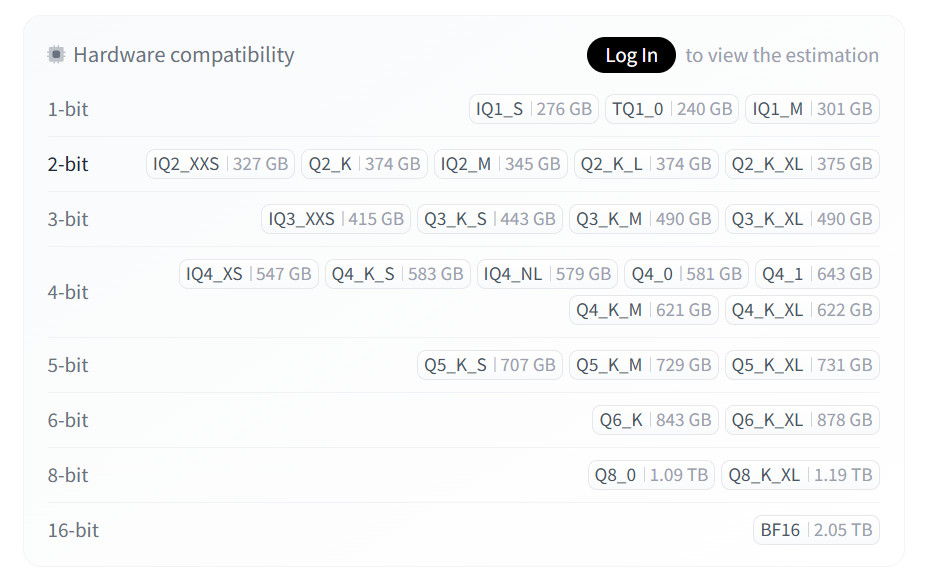
新出现的术语:
- IQ1_S / IQ1_M (276 GB / 301 GB):
I(Imatrix): 基于重要性矩阵 (Importance Matrix) 的量化。- 相关链接
- TQ1_0 (240 GB):
T(Ternary): 三值量化。权重的值只能是{-1, 0, 1}或者是特定的三个数。
- Q2_K_XL (375 GB):
Q2: 2-bit 量化。K: K-Quants(混合精度)。XL: 又来一个后缀。普通的llama.cpp只有 S/M/L。这里的 XL 应该是特调的“超大杯”。- 为什么叫 XL? 对于 MoE 模型,专家数量很多。XL 可能意味着它保留了更多“共享专家”或关键层的精度,虽然叫 Q2,但实际体积比普通的 Q2 要大。
Qwen3 系列
Qwen3 - a Qwen Collection 又发现新词了:
1. Thinking vs Instruct vs Base
据说是模仿 OpenAI o1 / DeepSeek-R1 的新分类。
- Base Model:原始模型,进行了预训练 Pre-training,能够预测下一个字,适用作为下游任务的底座(如在此基础上进行微调),或者用于单纯的文本补全任务。
- Instruct / Chat Model:在 Base 模型的基础上,经过了监督微调(SFT)和人类反馈强化学习(RLHF),理解意图与遵循指令。它学会了“对话”的模式,知道当用户提问时,应该回答而不是续写。
- Thinking / Reasoning Model:通过特殊的强化学习(RL)训练,学会了在输出最终答案前,先生成一段思维链(Chain of Thought, CoT)。自我感觉 thinking 确实聪明不少。
2. 命名规则:235B-A22B (MoE 架构)
235B(Total Params): 模型总共有 2350亿 个参数。硬盘占用极大,显存需求极大。A22B(Activated Params): A 代表 Active。意思是当你问一个问题时,并不是 2350 亿个参数都在动,只有 220亿 个专家被激活参与计算。
Part 6: 其他量化格式
1. FP8 (Floating Point 8)
例如:Qwen3-235B-A22B-Thinking-2507-FP8
- FP8 是原生浮点格式,会比 FP16 快,虽然精度低一些。
- 新显卡内置 FP8 计算单元,可以硬件加速,如 H100, RTX 4090 (Ada 架构)。
2. GPTQ (Generative Pre-trained Transformer Quantization)
例如:Qwen3-235B-A22B-GPTQ-Int4
- 技术原理: 逐行量化。它利用数学方法(Hessian 矩阵)来计算:“如果我把这个权重删减了,对输出误差影响大不大?”然后进行补偿。
- 特点:
- 静态: 需要一个“校准数据集”先跑一遍,一旦压好了,文件就定死了。
- 显卡友好: 在 NVIDIA 显卡上优化极好。
3. AWQ (Activation-aware Weight Quantization)
例如:Qwen3-32B-AWQ
- 把 FP16 压缩为 INT4 格式。
- 原理:在 AWQ 之前,很多量化方法只盯着**权重(Weights)**看。但 AWQ 作者发现:并不是数值大的权重才重要,重要性取决于“激活值(Activation)”。
- 模型中只有 0.1% - 1% 的权重是重要的 (Salient Weights),它们对应的激活值非常大。只要保护好这 1% 的权重,整个模型的精度就能保住。
- 流程:与 GPTQ 相比不调整权重数值,只计算缩放系数:
观察:找一段校准数据喂给模型,看看哪些通道的激活值特别大。放大:把这些对应的重要权重数值“放大”。缩小:为了保证数学结果不变,同时把输入的激活值“缩小”。量化:经过放大后的权重,在进行量化(四舍五入)时,相对误差会变小。
4. MLX
- MLX: 是苹果专门为 M1/M2/M3/M4 芯片写的原生代码库。它能深度调用苹果芯片的 NPU(神经网络引擎)。